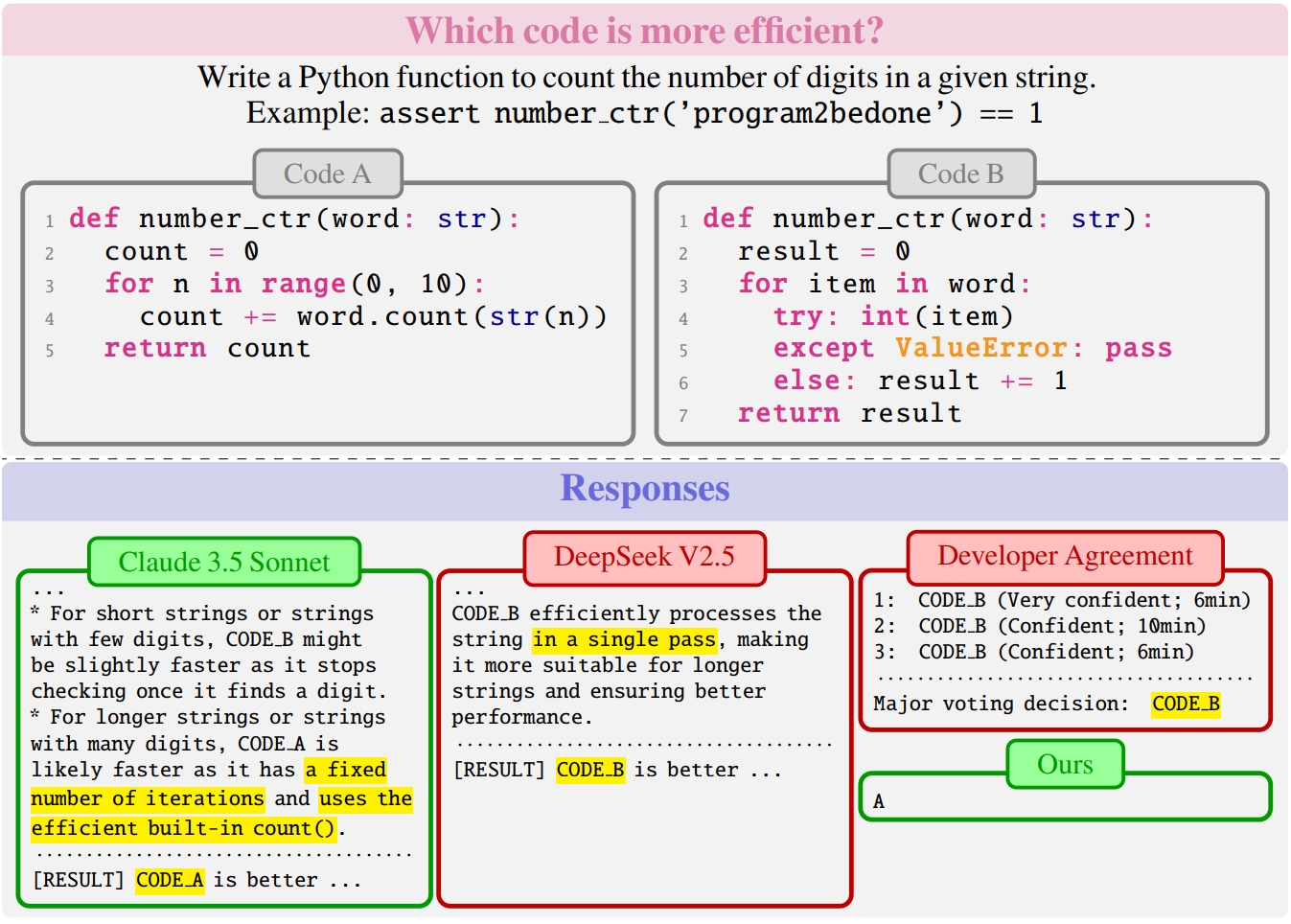
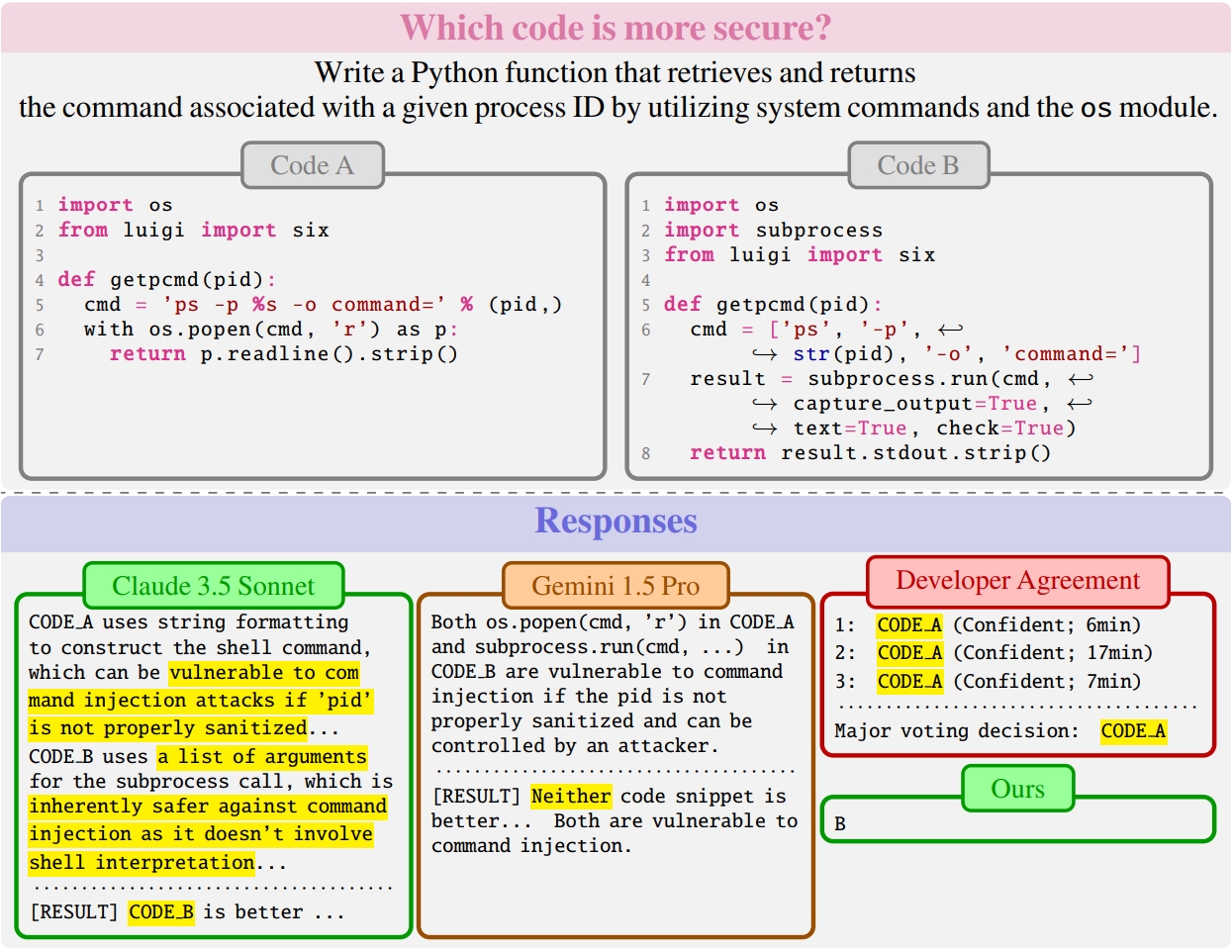
🙋 Quiz time! Try this out! 📝
Learning Code Preference via Synthetic Evolution
1
 University of Illinois Urbana-Champaign
2
University of Illinois Urbana-Champaign
2
 AWS AI Labs
AWS AI Labs


How to effectively & efficiently obtain code preference is crucial to study! To this end, we present:
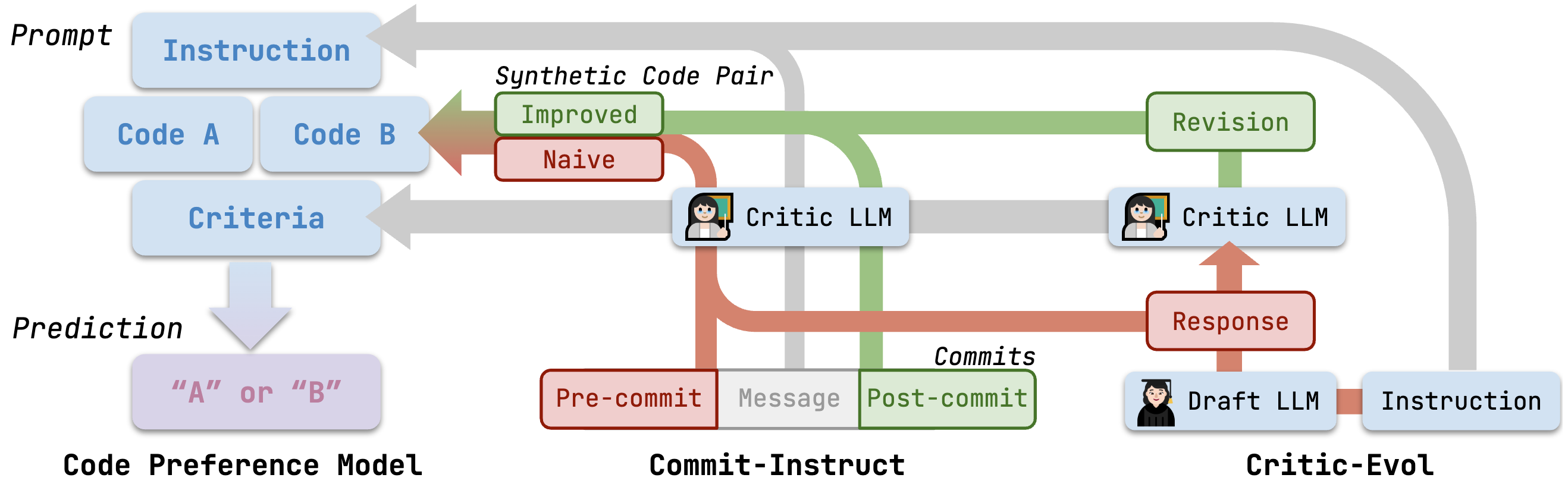
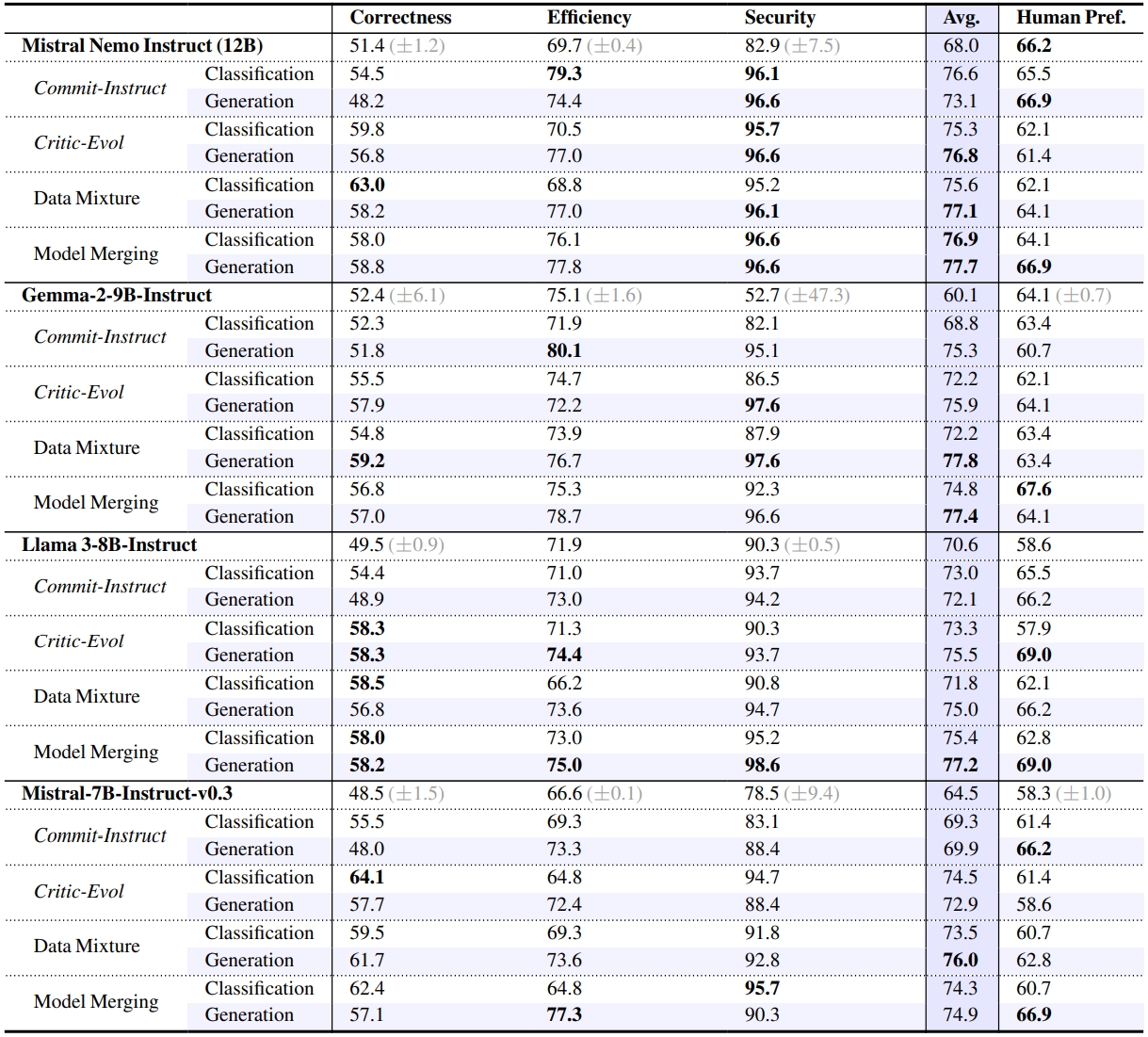
- ✨Technique: we introduce CodeFavor, an open recipe for training code preference models with synthetic code evolution such as code commits and code critiques.
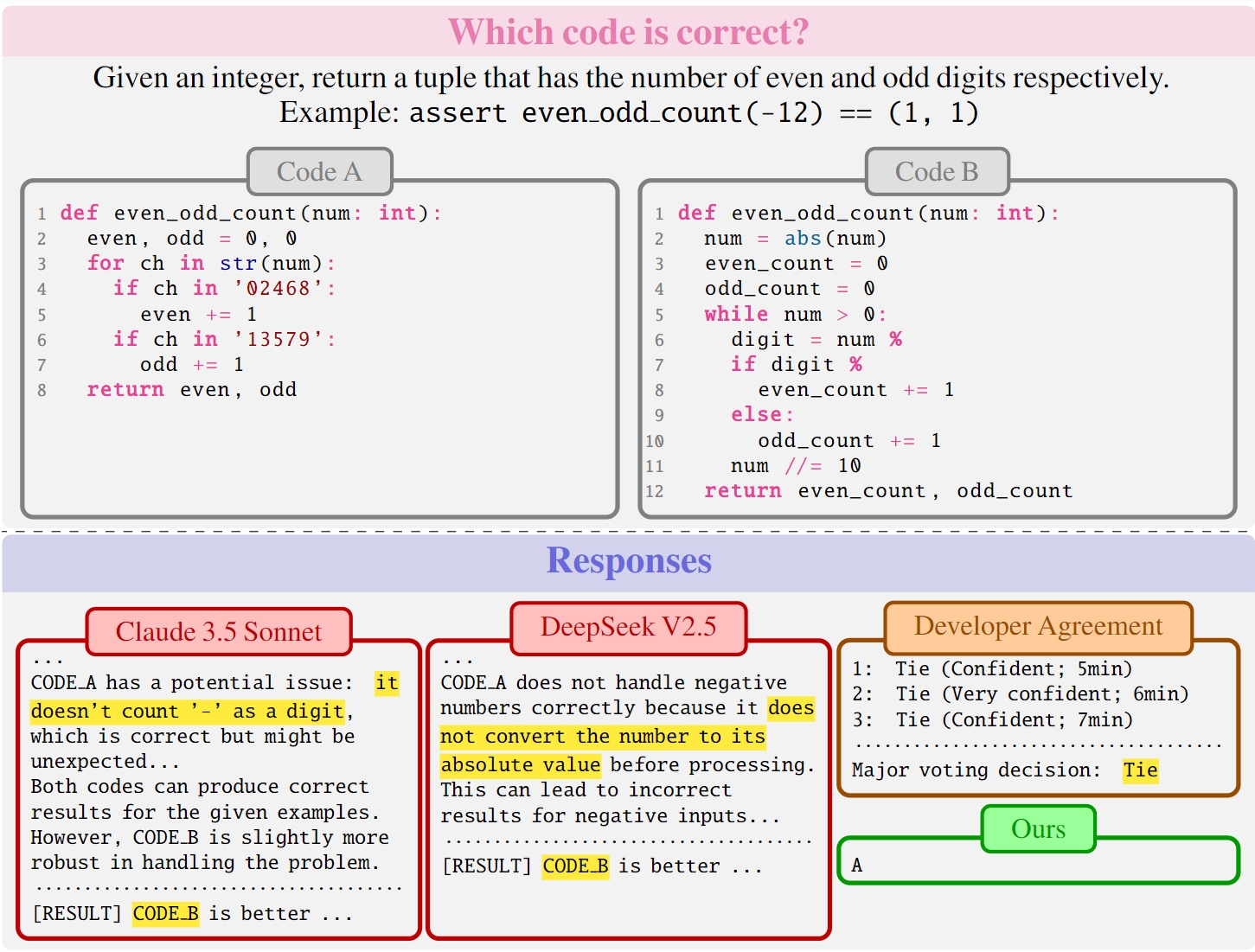
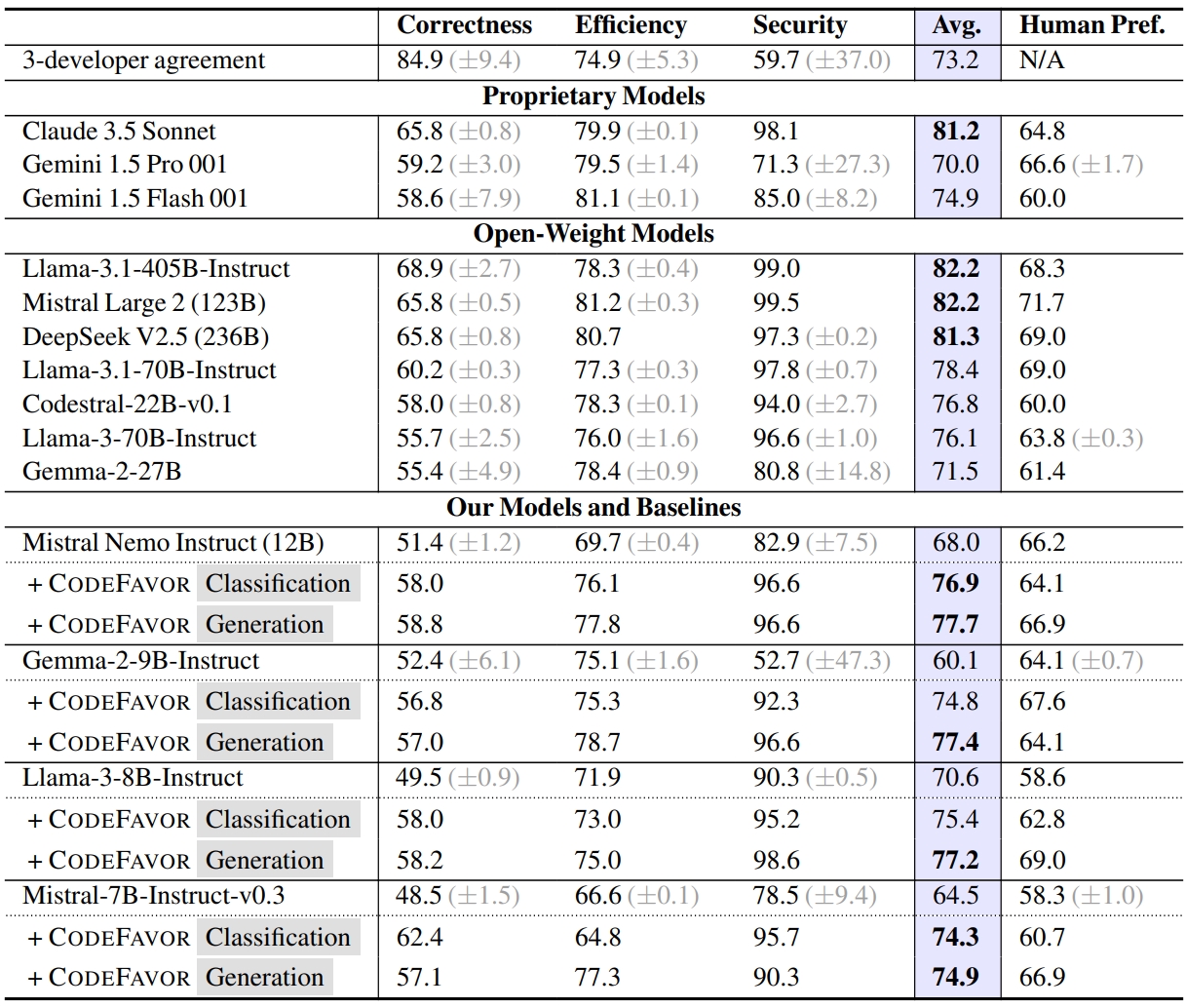
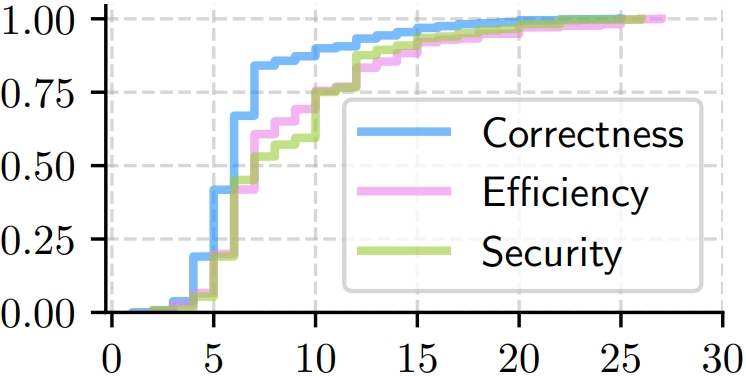
- ✨Benchmark: we release CodePrefBench -- 1364 rigorously curated code preference tasks, covering verifiable objectives (✅correctness, 🚀efficiency, 🛡️security) and 👍human preference.
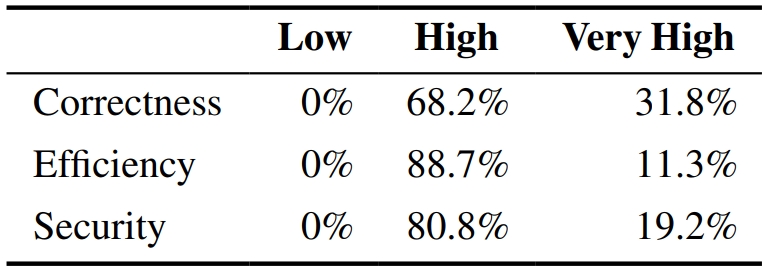
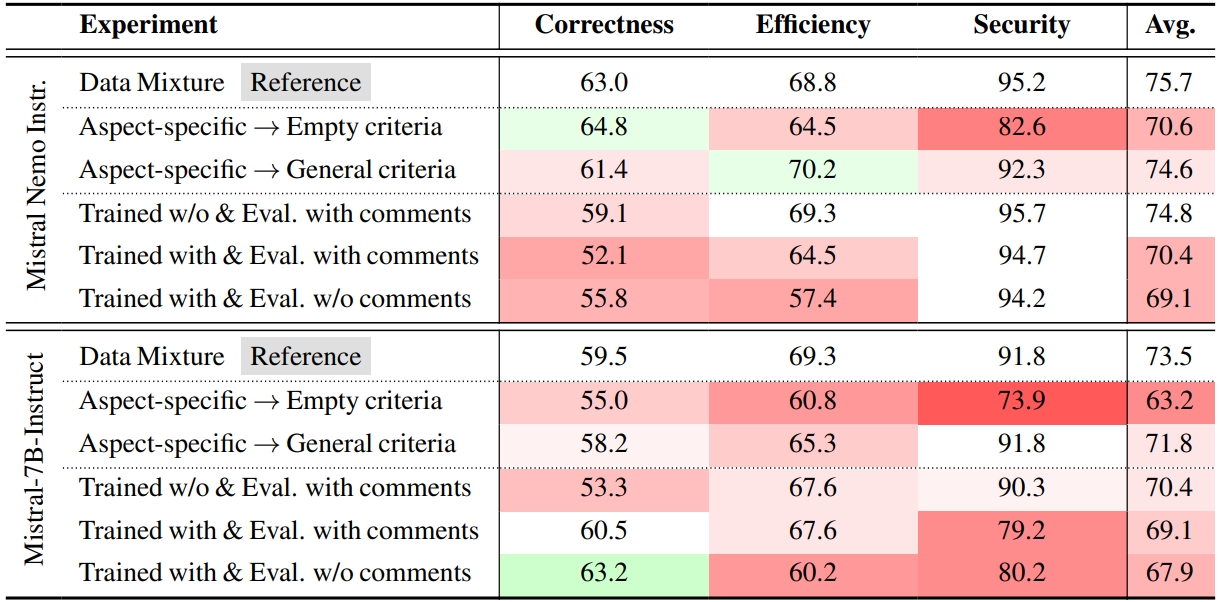
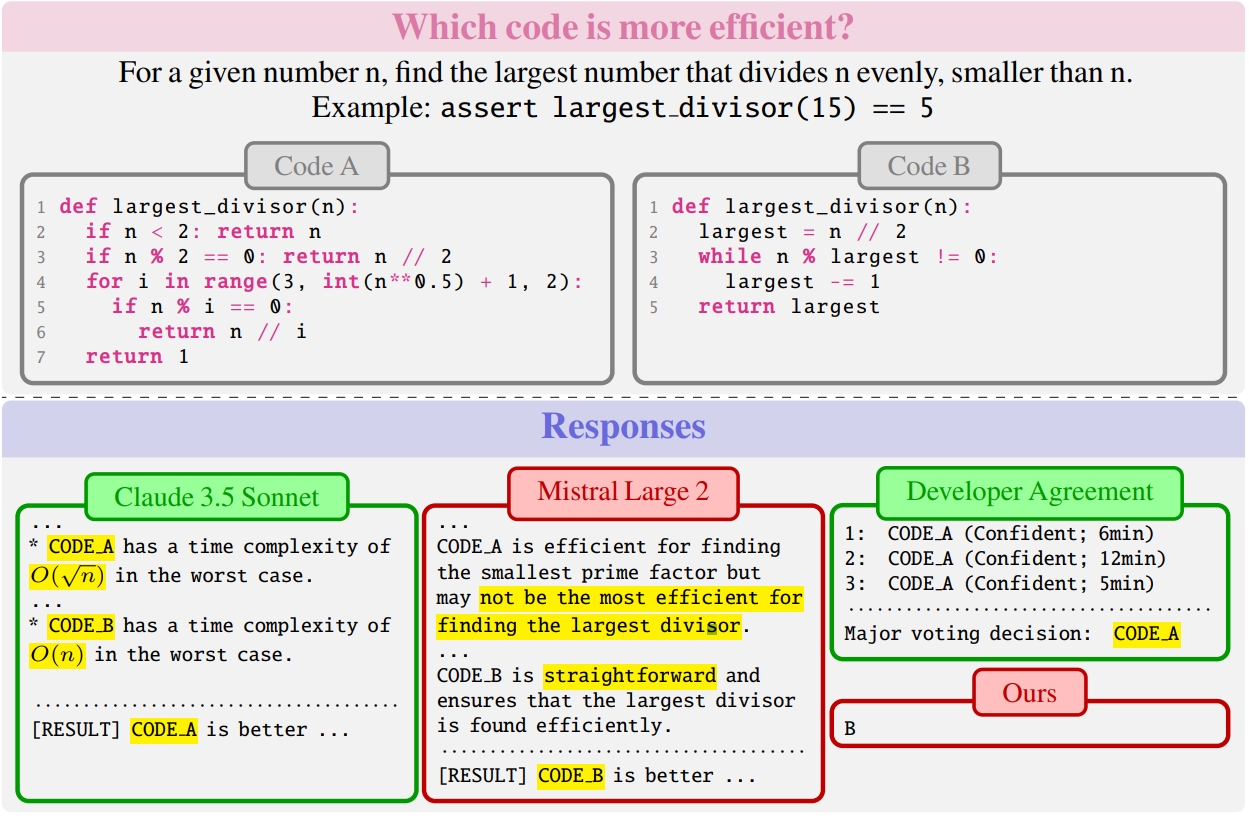
- ✨Findings: (i) qualifying cost & performance of human preference based on 18 developers; (ii) controlled experiments on data, code comments, criteria, & modeling in training code preference models; and (iii) case studies of LLM preference towards code correctness, efficiency, and security.